Configuring Multi-Session with Sequentum Cloud
Sequentum Cloud provides a highly efficient feature that allows agents to run in multiple or parallel sessions. This capability significantly reduces the runtime of agents, enabling them to complete their tasks more quickly. By executing agents concurrently, Sequentum Cloud ensures that large-scale data extraction and processing operations can be handled with greater speed and efficiency, which is particularly beneficial for businesses with tight data delivery deadlines.
The ability to run agents in parallel sessions means that the workload is distributed across multiple resources, allowing for faster data collection, transformation and delivery. This not only optimizes the performance of data operations but also minimizes delays, ensuring that businesses can meet their data-driven goals in a timely manner.
Additionally, this feature is highly scalable, making Sequentum Cloud an ideal solution for businesses of all sizes that require flexible and reliable data extraction capabilities. Whether the task is to handle massive datasets or to meet real-time data delivery requirements, Sequentum Cloud's parallel session feature empowers users to achieve high performance and consistent results with minimal downtime.
In summary, Sequentum Cloud’s parallel session feature is a game-changer for companies seeking to streamline their data extraction processes. By allowing agents to operate simultaneously, it not only accelerates the workflow but also enhances operational efficiency, ensuring that critical data is delivered on time and with precision.
In Sequentum Cloud, sessions enable you to run multiple instances of the same agent simultaneously. This feature is particularly useful for breaking down large web scraping tasks, allowing several instances of an agent to work in parallel on different portions of the task.
Sequentum Cloud efficiently divides large tasks by splitting list entries into smaller subsets. Each instance of the agent is then assigned to process one of these subsets. For example, if you are scraping data from a long list of starting URLs, Sequentum Cloud can split the list into smaller chunks, enabling one instance of the agent to handle the first subset while another instance works on the next, and so on. This parallel processing significantly speeds up data extraction, especially when dealing with large datasets.
Although Sequentum agents already use multithreading to distribute work internally, running multiple sessions often provides an even greater performance boost. This is because, while multithreading can efficiently divide tasks, it sometimes requires threads to wait for each other to complete before moving on to the next stage. For example, when scraping through paginated data, some threads may finish processing one page faster than others, but the agent must wait for all threads to complete before moving to the next page.
With Sequentum Cloud’s multiple session feature, each instance of the agent operates independently. This means that one instance does not need to wait for another to finish its task, providing a more seamless and faster data extraction experience. Furthermore, these parallel sessions can be distributed across multiple servers, maximizing performance by leveraging multiple computing resources at once.
In summary, Sequentum Cloud’s session capability offers a powerful solution for businesses dealing with large-scale data extraction. By allowing multiple instances of an agent to work independently, it enables faster and more efficient processing, especially for time-sensitive or high-volume web scraping tasks.
Note: We can use parallelism option/process list in parallel only when using a list like Data List or Page Area List. Below is the detailed explanation for the same:
Using Data List - For Example, if we are having a data list of 100 inputs and we are willing to run it in parallel sessions for faster execution, then firstly we need to go to the Options tab in Data List command, then to the List menu, then we need to check the Process List in Parallel checkbox(refer to below screenshot)

By using above properties, inbuilt multithreading will automatically work and will split the inputs into multiple desired chunks automatically.
Using Page Area List - For Example, if we are having a data list of 100 selections and we are willing to run it in parallel sessions for faster execution, then firstly we need to go to the Options tab, then to the List menu, then we need to check the Process List in Parallel checkbox(refer to below screenshot)

Scheduling Parallel Run Task
Users also have the option to split inputs and execute them in parallel. This feature allows users to divide large inputs and process them concurrently for more efficient execution.
By checking the 'Split up inputs and process in parallel' checkbox, users can configure handling of larger inputs for parallel processing.

Parallel Processing : By enabling the Parallel Processing option, users can configure how the input data is divided and processed concurrently.
Total Runs: Specifies the total number of splits for the input data.
Concurrency: Defines the number of executions that will run simultaneously
Export: Allows users to choose whether to export the data as a combined output or separately for each session.
Monitoring Runs in Progress
Once the agent is in execution, navigate to the agent details page where the status will be displayed as 'Running.' To monitor the live execution, click the 'View Live Information' button, as shown below:

After selecting the option mentioned above, a live stream of the agent's execution will be shown, enabling users to monitor progress in real-time.

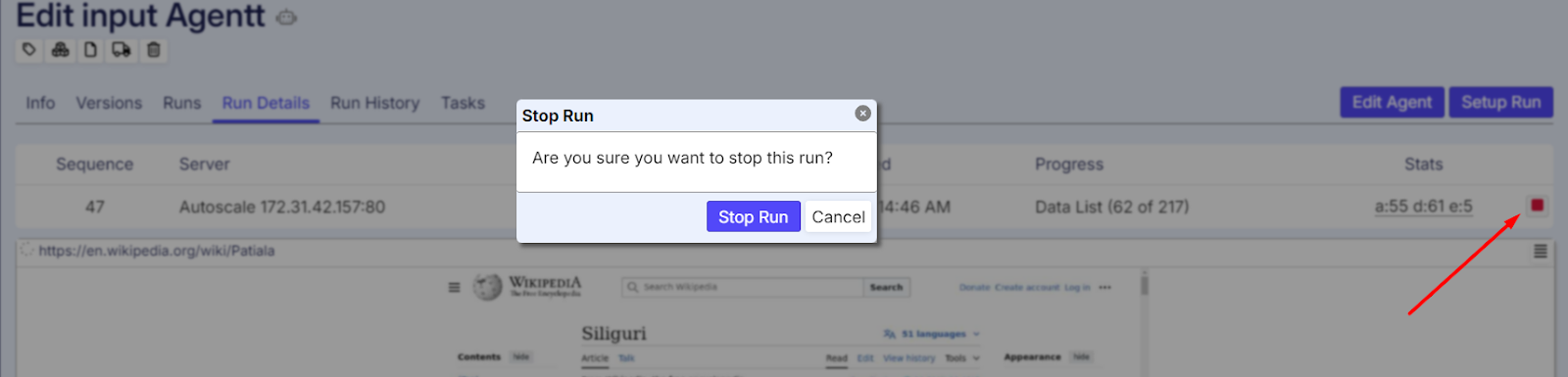
Stopping a Run
Users can stop a running execution at any time by clicking the 'Stop' button. When this happens, the status will be updated to 'Stopped' in the 'Status' column on the Runs page as shown below:
Reviewing Run History
This option allows you to view the Run History of the agent. Run history page displays the complete run history of the agent job schedule.
You can navigate to the Run history page via the below option:

Users can view the details of a specific agent execution by clicking the 'View Run Details and Files' button. On this page, users will find the historical logs and output files tailored to their requirements.
