Remove Duplicate
The Remove Duplicates option helps maintain data quality by identifying and removing redundant records during the extraction process. This ensures data integrity and optimizes storage usage.
This article explains how to enable and configure Remove Duplicates.
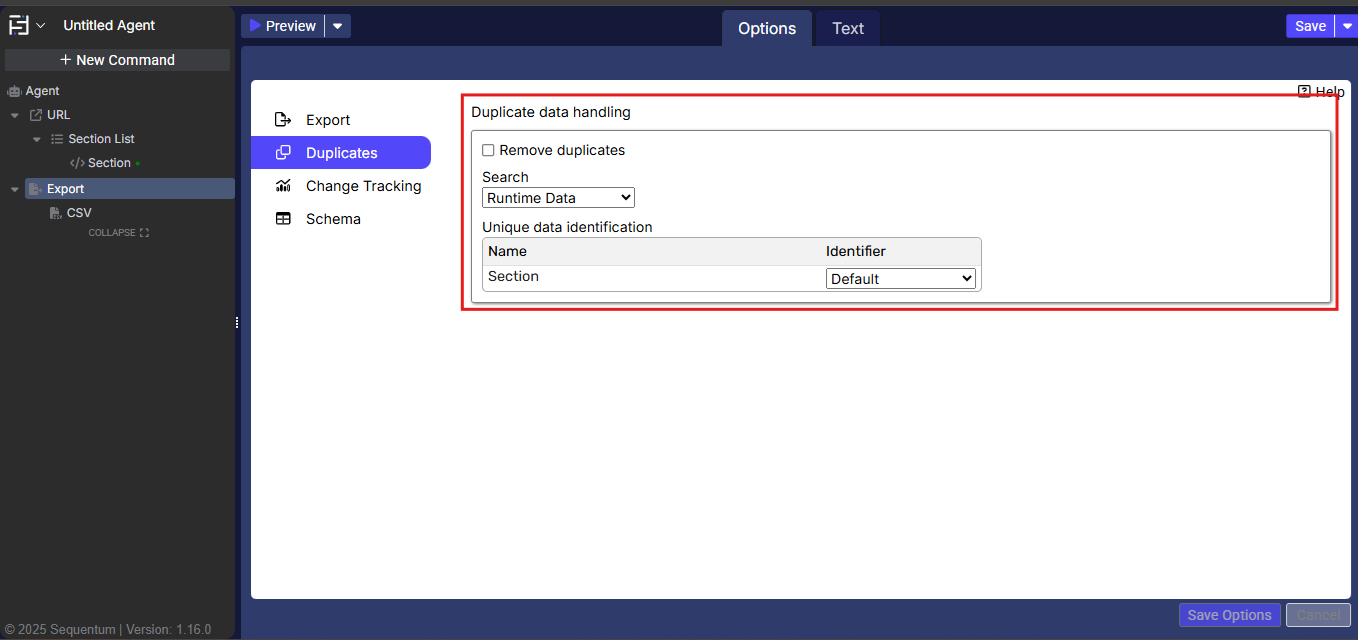
Enable Remove Duplicate
Follow these steps to turn on duplicate removal:
Click on the Export Command.
Navigate to the Duplicates option.
Within the Duplicate data handling section, select the Remove duplicates checkbox.
Once enabled, configure the available settings as described below.
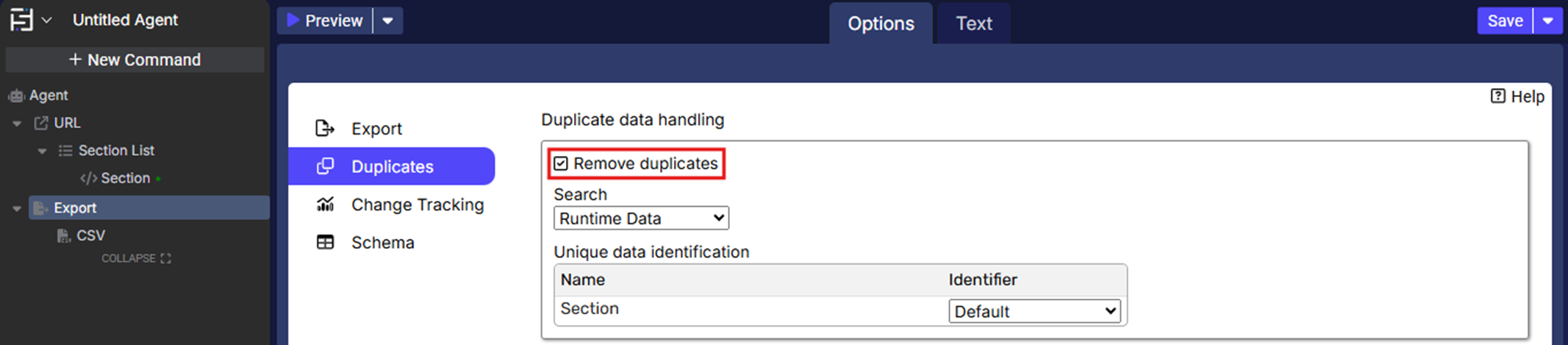
1. Search
The Search dropdown specifies where duplicate checks will be performed. Available options include:
Runtime Data: Compares records only within the data extracted during the current run.
Last Extracted Data: Compares records against the most recent extraction.
All Data: Compares new records against all available extracted data.
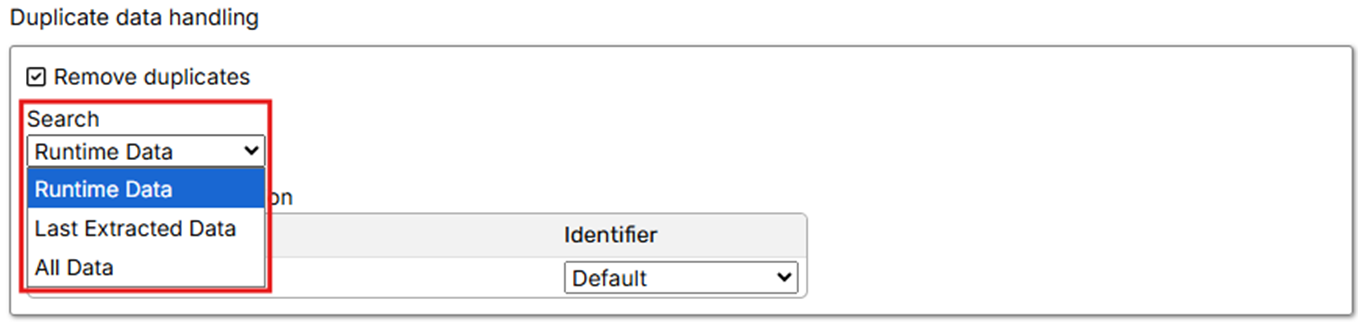
2. Unique data identification
This setting determines how a unique record is defined. A record is treated as a duplicate if all of its Identifier columns match another record.
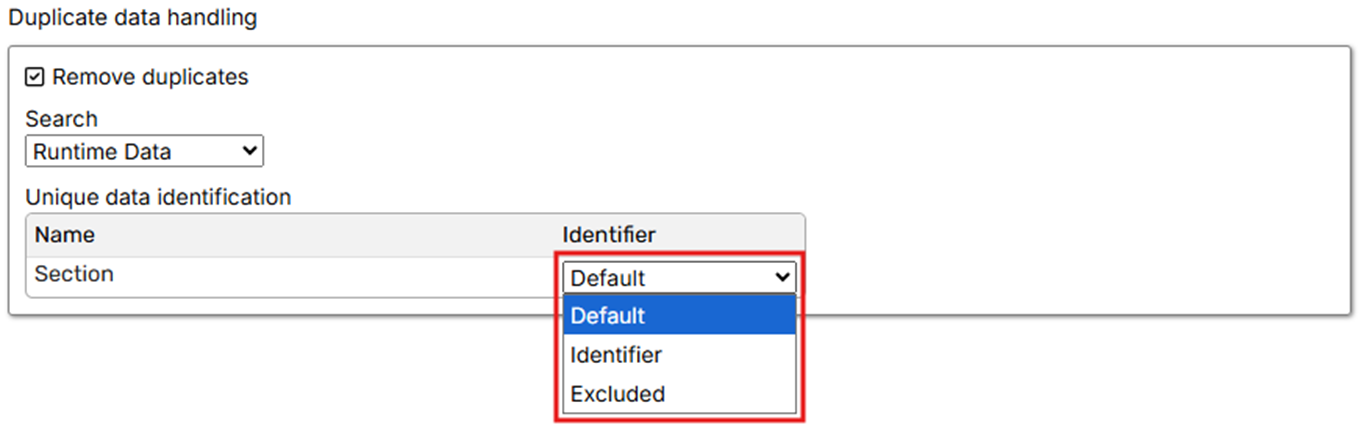
Each column can be assigned one of the following statuses:
Identifier: This column's value will be used as a key to detect duplicate records.
Excluded: This column will be ignored during the duplicate check.
Note:
By default, all columns are set to Identifier. To modify a column's status, select the columns and choose the desired option.
Example
The following screenshot is a simple example demonstrating the use of Remove duplicates.
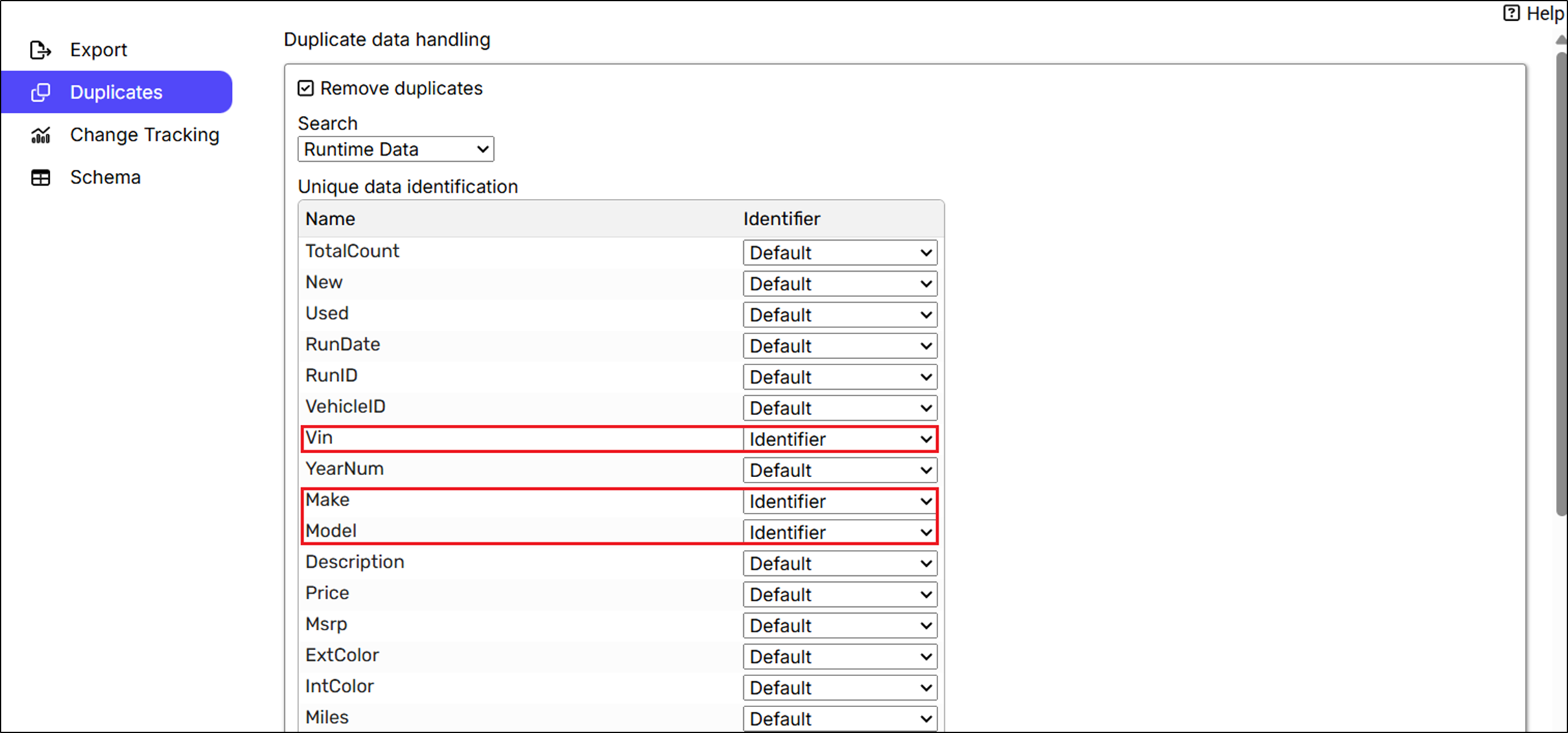
To Remove duplicates from the data, the user needs to enable the check box and select the Unique data identification columns on the basis of which the data is de-duplicated.
Kindly note, data is de-duplicated only on the basis of the columns that are exported. A column set to ‘not Export’ data is not taken into consideration for removing duplicates from the data. After the agent completes the data extraction process, it then initiates the data de-duplication process on the basis of Identifier columns selected before generating the final output file.
In the above example, there are three Identifier columns “Vin”, “Make” and “Model” on the basis of which the extracted data will remove duplicates. If all the three values are the same for more than one record, the agent will remove all the duplicates before exporting the distinct record to the file.