Sequentum Cloud Commands Reference Overview
Sequentum Cloud commands are equipped with a variety of properties, allowing users to tackle the complexities of modern data extraction tasks. Each command comes with a unique set of options, while some properties are shared across multiple commands. These options enable users to efficiently extract and export data in the format of their choice.
You can explore and configure command properties by following these simple steps:
Follow these simple steps to explore and configure command properties:
Access Command Options: Click on the options icon in the top right corner of any command.
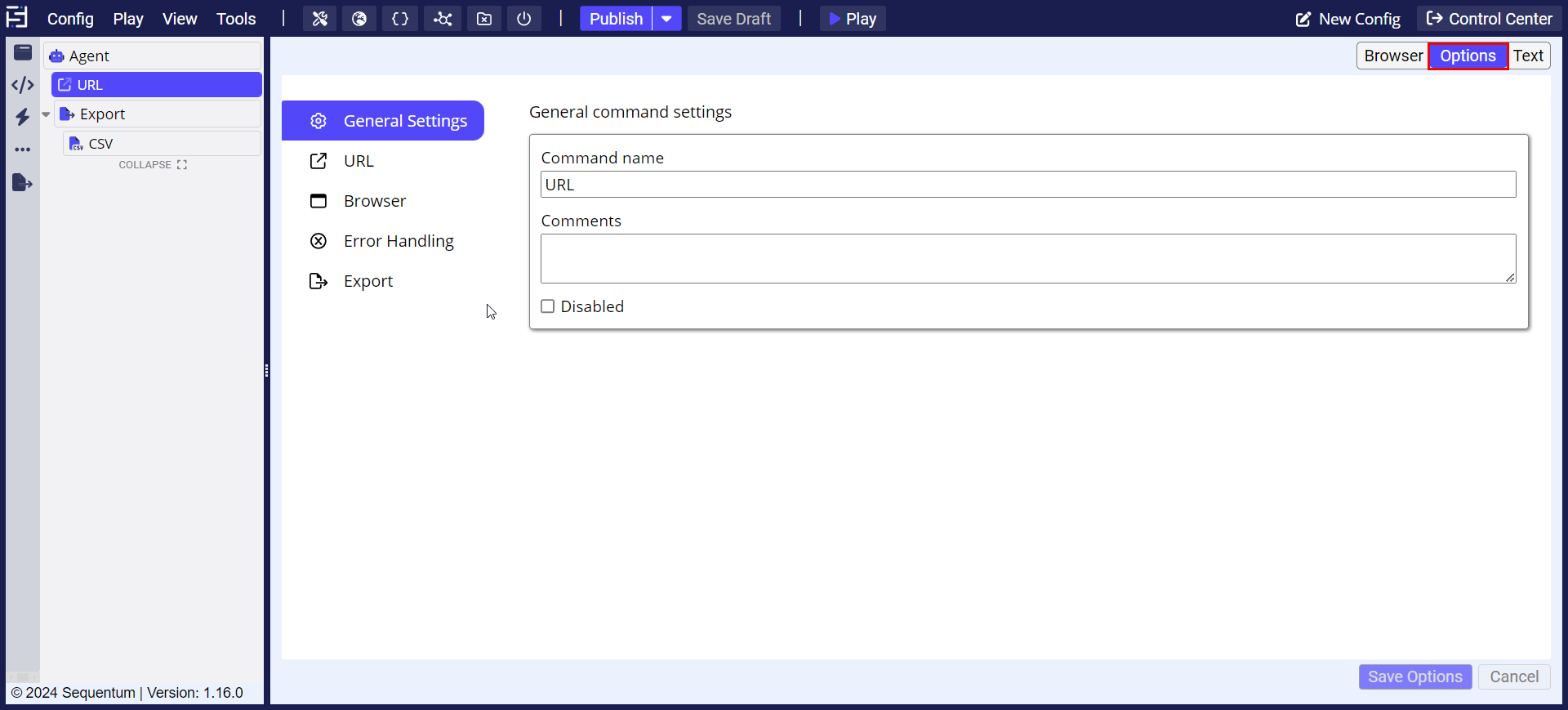
View Command Properties: This will display the properties associated with the selected command.
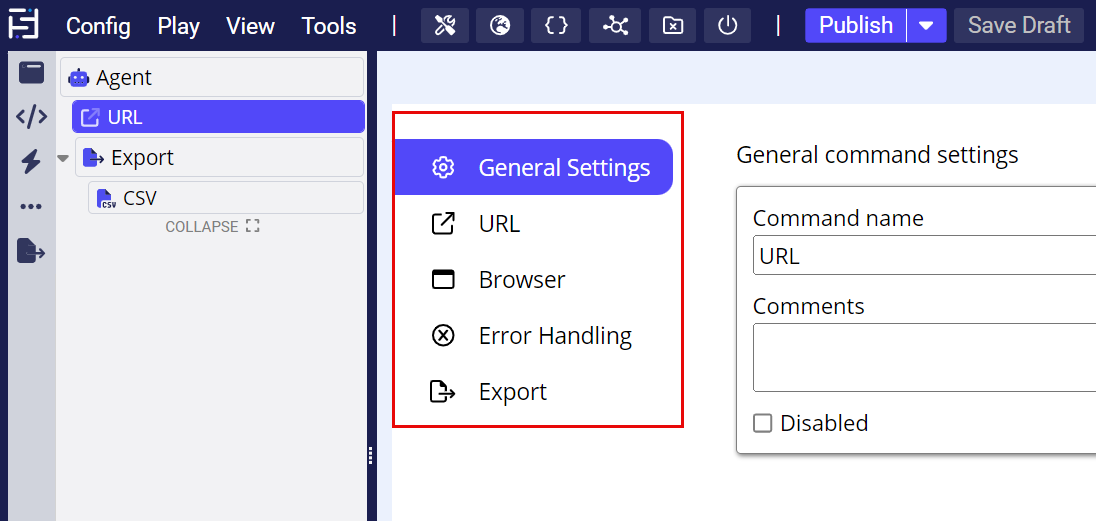
Adjust for Specific Needs: In most web-scraping cases, the default property settings will be sufficient. However, you may need to modify them based on your specific requirements and the website's behavior.
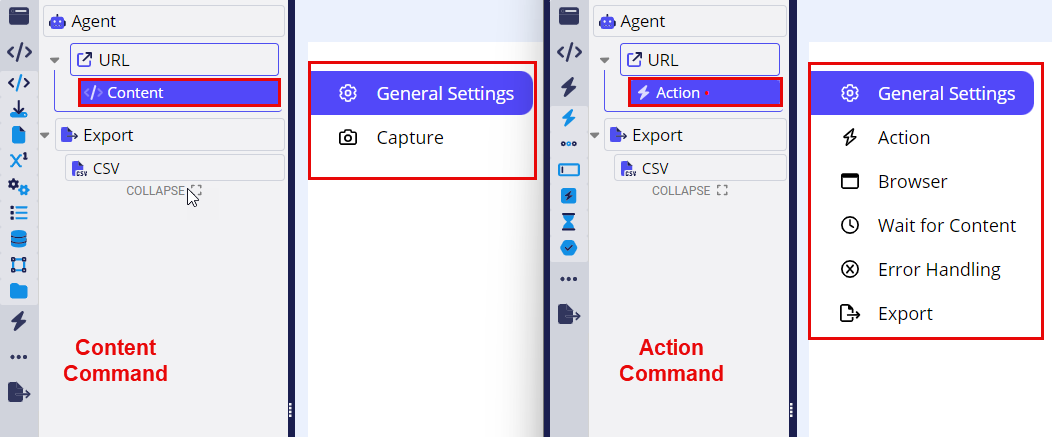
Leverage Shared and Unique Properties: Different commands have unique sets of properties, along with some shared ones that provide flexibility across commands. For example, you can compare the Action Command Properties with the Content Command Properties to understand their differences. As shown in the screenshot below, the Content Command properties include only two options: General Settings and Capture Options, while the Action Command properties feature General Settings, Browser, Dynamic, Wait for Content, Error Handling, and Export Options.
Below are some specific important properties that are associated with each command that one needs to be aware of when using that command in totality.
Branch Command
Data Value Command
Data List Command
Page Area List Command
Page Area

Input Action
Wait for Content

Exit
Retry
Fail
Script
File Link
Link Repeater
URL:
Link:
Open Page:

Open Content:

Page Area:

Group:

Branch:
Test:

Convert Content:

Action:
Content:

File:
Also General Settings is a common setting in Each and every command except the Agent command.

Sequentum Cloud Commands
Agents in Sequentum Cloud execute a sequence of commands in order to extract data from websites or other online resources. The basic principles remain similar to Sequentum Enterprise and Desktop, with some nuances specific to the cloud environment.
Command Types in Sequentum Cloud:
Sequentum Cloud categorizes agent commands into four main types based on their functionality:
Browser Commands:
These commands handle navigation and interaction with web pages. They are essential for loading content, following links, and working with dynamic pages. Browser commands form the basis of any web scraping project by dictating how the agent moves through the web and accesses the required data.
URL: Loads a specified URL in the browser to start or continue scraping. This is the command that initiates the agent’s journey to the target web page.
Link: Clicks a link on the current page to navigate to another page. This is used for exploring deeper into the site, following hyperlinks to gather more data.
Link Repeater: Follows a set of links found on a page, repeating actions for each link. This is helpful when scraping multiple pages with similar content (e.g., paginated product listings).
Open Page: Reloads or navigates to a new page within the browser. Useful for resetting the page state or moving to a new section of the site.
Open Content: Opens and interacts with dynamic or embedded content, such as pop-ups, iframes, or hidden sections of a web page, allowing the agent to extract data from additional layers.
Extract Commands:
Extract commands focus on gathering data from web pages or input sources. These commands are the heart of web scraping as they pull out the information you want to capture, whether it's text, files, or specific data values. They allow for transformation and processing of data as well.

Content: Extracts text or HTML content from a web element, storing it as output. This command is crucial for pulling specific data fields such as product names, prices, or descriptions.
File: Downloads a file (PDF, image, etc.) from the web and stores it locally or in the cloud, useful for preserving documents or media.
File Link: Captures the URL of a downloadable file, allowing the link to be saved or followed later to retrieve the file.
Data Value: Extracts specific values from input sources (like a CSV file or database) to use within the agent. It dynamically integrates external data into the scraping process.
Convert Content: Converts the captured data from one format to another, such as converting HTML to plain text, making it easier to export or analyze.
Page Area List: Iterates through a list of page areas (e.g., rows in a table), extracting data from each section. Useful for processing structured data on a web page.
Data List: Extracts data from structured lists or tables. This command helps in capturing multiple rows or columns of data at once, improving efficiency.
Page Area: Captures content from a specific region of the page, such as a sidebar, header, or footer. It helps target distinct sections of a web page layout.
Group: Groups multiple commands into one unit, organizing them logically for better readability and flow. This is useful for structuring complex agents with many interrelated actions.
Action Commands:
Action commands are used to perform interactions on the web, such as clicking buttons, filling out forms, or waiting for certain content to load. They simulate user actions, enabling agents to interact with websites in a way that facilitates data extraction, especially from dynamic or interactive web pages.
Action: Performs an action such as clicking a button, navigating through menus, or triggering JavaScript events. This is vital for interacting with interactive elements on a page.
Action Repeater: Repeats an action multiple times, such as clicking all buttons in a list or navigating through multiple links. It is useful for repeated interactions on similar elements.
Input Action: Fills out form fields with specified values (e.g., entering text into a search box) before submission. It is essential for interacting with web forms and dynamic pages.
Page Action: Executes actions related to the page itself, such as scrolling, refreshing, or selecting elements, enabling better navigation through complex pages.
Wait For Content: Delays the execution of commands until specific content is detected on the page, ensuring that dynamic content has fully loaded before scraping.
Test: Validates the presence or value of content, ensuring that the page or action has met certain conditions before proceeding. This is useful for error handling and ensuring scraping accuracy.
Other Commands:
This set of commands handles additional logic and control structures, like branching, retrying actions, or running scripts. These are utility commands that enhance flexibility, error handling, and control over agent workflows, helping agents adapt to different situations.
Branch: Creates conditional paths within the agent, allowing it to follow different actions based on the outcome of previous commands (like "if" statements in programming).
Exit: Terminates the agent early if specific conditions are met, such as when all relevant data has been collected or if a failure occurs.
Retry: Repeats a command that failed due to temporary issues like network timeouts. It is crucial for improving agent reliability and overcoming temporary obstacles.
Fail: Forces the agent to stop and log an error if critical conditions are not met. This ensures that issues are flagged and reported accurately.
Script: Runs custom scripts, allowing for advanced automation or manipulation of data. This adds flexibility for handling complex or unique scenarios.
Export Commands:
Once data is captured, it needs to be exported. Export commands manage the output of scraped data into various formats and destinations, such as CSV files, cloud storage services (S3, Google Drive), or even complex data warehouses like Snowflake. These commands define how and where your data is stored after extraction.
CSV: Exports the scraped data into a CSV file format, which is widely used for spreadsheet applications and data analysis.
JSON: Saves the output in JSON format, suitable for structured data and integration with APIs or other software applications.
S3: Uploads the scraped data to an Amazon S3 bucket, providing scalable and secure cloud storage for large datasets.
Google Sheets: Sends data directly to Google Sheets, enabling easy collaboration, sharing, and real-time access to the scraped data.
Google Drive: Exports the data to Google Drive, offering secure cloud storage for easy access from any device.
FTP: Transfers the output data to an FTP server, allowing integration with legacy systems or private network storage solutions.
Snowflake: Loads data into a Snowflake data warehouse, providing scalable storage and processing for large datasets and advanced analytics.
Export Script: Executes a custom export script to handle complex export scenarios, including data transformation and integration with external systems.