Content Command
The Content command is typically the most commonly used feature for capturing information from web elements. It allows users to extract various types of content, such as text, URLs or HTML from specified elements on a webpage. This versatility makes it an essential tool for data collection and web scraping, enabling users to gather relevant information efficiently and effectively.
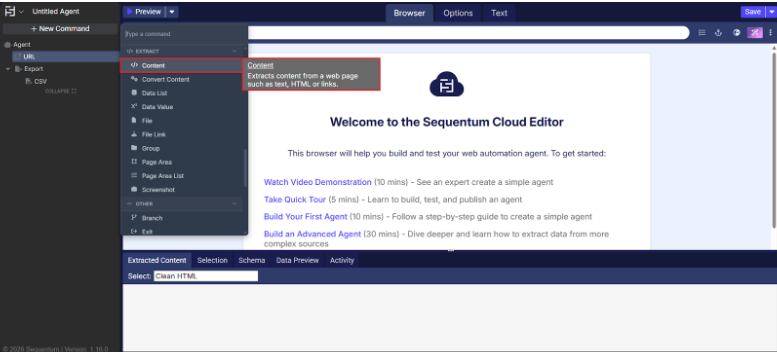
The Content command is located under the Extract category in the command palette (refer below snapshot)
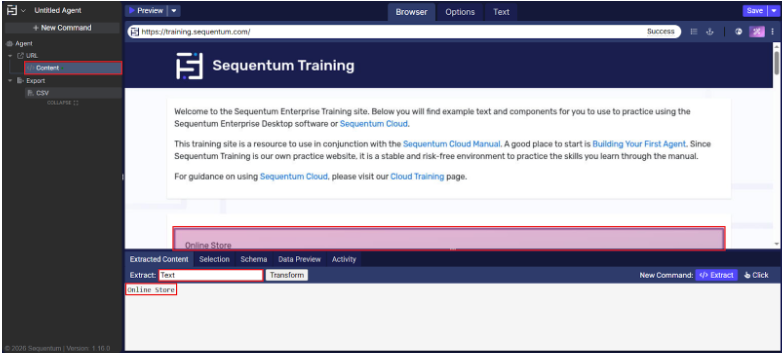
The screenshot below shows the simplest example where the Content command can be used:
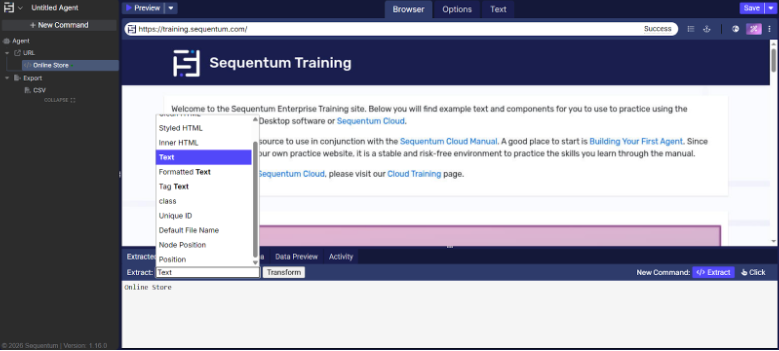
The screenshot below shows the example of types of data which can be extracted from when we use the Content command
In order to make the optimum use of the Content command, we can configure the options as shown in the below screenshot, as per the user requirement.

Command Configuration
The configuration screen for the URL command has three tabs viz. Browser, Options, and Text. Use the Browser tab to select command XPath and apply selection transformations. Use the ‘Options’ tab to set the command name and other command properties. Use the Text tab to navigate to the text of the agent where the command part is present.

Command Properties
On the Options tab of the command, we have two options:
General Settings
Capture
The different types of data which we can extract using content command are given table:
Clean HTML | This option will extract the HTML but removes all the attributes that are used to style the HTML. |
Default File Name | Returns any file name specified by a response from a web server. If no filename is specified, then a file name from a href attribute is extracted or from a unique identifier if the href does not exist. This attribute is mostly relevant to file capture commands. |
Formatted Text | This option will extract the entire HTML of the chosen web element and insert line breaks where appropriate. |
HTML | This option will extract the entire HTML of the chosen web element, including the HTML of any child elements. |
Inner HTML | The entire HTML of all child elements of the selected web element, but not the tag HTML of the chosen element itself. |
Node Position | The position of the web elements among all siblings. |
Position | The position of the web element among siblings of the same type. |
Styled HTML | This option will extract the HTML, but removes all the attributes that are used to style the HTML, except the attributes used for inline styling. |
Tag Text | The text of the selected web element, excluding the text of any child elements. |
Text | This is the text that displays in the web browser and is the most common choice (it's also the default). |
Unique ID | A unique identifier. The web selection is ignored if this option is selected. |
Transform
The Content command allows you to use regular expressions, JavaScript , C# or a Python script to transform the extracted content. In some cases, you may need to write regular expressions or use a script to clean the data that you extract. You can also separate data for e.g. separating out the elements of a postal address into a separate field.
Example: Consider a case in which you want to extract product data that includes a price of $400. You could use a transformation script to strip off the "$" character and leave only the numeric value.
General Settings → General command settings
These settings allow you to rename the command, add comments for clarity, and enable or disable the command as needed.

Command name: This property specifies the name of the command.
Comments: Provides a field for entering metadata or a brief description regarding the command. These annotations are used internally to provide context for developers or team members. Comments are not part of the exported data and are only used for documentation purposes within the configuration.
Disabled: This checkbox allows the user to disable the command. When checked, the command is ignored during execution. By default, it is unchecked.
Capture → Selected Content
This shows the content selected by the command on the current page. If no content is selected on the current page or a selection is missing on the current page, then it will show the below Message as No selected Content.

When missing: This option specifies what happens if the selection does not exist in the current page. The drop-down provides the option to select the action to be performed when a selection is missing. The Default Value is Warn.
Fail: The agent will stop and return an error, or if there are parallel commands, it will log the error and move to the next parallel command.
Warn: The agent logs a warning but continues processing further commands.
Ignore: The agent neither logs an error nor a warning, and it skips any child commands, moving to the next parallel command.
Passthrough: The agent ignores the error but continues to execute the child commands.
2. When hidden or disabled: This setting controls how the agent handles element selection based on their visibility or enabled/disabled state.
Select: The agent will select both visible and disabled elements that match the XPath.
Ignore: The agent will only select elements that are present and enabled (i.e., the XPath matches and the element is interactable).
Selected content: This shows the content selected by the command on the current page. If no content is selected or a selection is missing on the current page then it will show the message as “No selected Content”.
Capture → Capture Settings

Content Type: The Content Type setting is a crucial feature that allows you to specify the format of the data which you have extracted. By selecting the appropriate data type, you ensure that the extracted information aligns with your specific needs and can be effectively utilized for various purposes. Here’s a detailed overview of the available options:
Text: All content will be captured as Short Text by default. Short Text content can be up to 4000 characters long.
Long Text: Long Text content is used to capture information that exceeds the 4000-characters. It allows for more extensive data collection, accommodating larger amounts of information without the constraints of character limits.
File: It includes documents, images or any other type of file, making it versatile for various data needs.
Integer: A whole number.
Float: A floating point number.
Date: Select this option if extracted date values are not associated with time.
Time: Select this option if extracted time values are independent of dates.
Date & Time: This option combines both date and time values providing a complete timestamp.
Boolean: A value that can be true or false. Boolean values are stored as 1 or 0 integer values.
Big Integer: A 64-bit signed integer.
Decimal: Represents a decimal floating-point number.
Export : This feature enables the extraction of content at the end of the process. By default, the checkbox is marked as checked, ensuring that the extracted content will be exported automatically unless you choose to uncheck it. This provides a convenient way to access your data after the extraction is complete.
When the Export option is enabled, you can customize your export settings. Available options include specifying the Export Name, enabling Tracking, allowing empty fields, selecting Format Style, choosing the Format and managing Validation Error Handling. These options are detailed below:
Export Name: This setting allows you to define the name of the column in the export schema. By specifying a clear and descriptive export name, you ensure that the data is easily identifiable and organized in the exported file, enhancing readability and facilitating better data management for users.
Tracking: This setting allows you to configure whether the command’s content will monitor changes between runs. By default, it is set to "Default," but you can choose from any of these three options: Default, Identifier, and Excluded. This flexibility helps you manage how changes are tracked during each run. This option is effective only when the Change Tracking feature is enabled in the Export settings of the command.
Default: This option enables tracking of changes, providing a detailed record of modifications.
Identifier: This setting specifies the certain captured content will be tracked for changes, allowing you to monitor only selected elements.
Excluded: This option excludes captured content from change tracking, ensuring that irrelevant data is not monitored.
Allow Empty: This setting determines how empty or missing values are handled in the captured content. This is crucial for managing data quality in various contexts.
Always: This option permits empty or missing values in the captured content, providing maximum flexibility.
Never: This setting disallows any empty or missing values, ensuring that all fields must be completed before export.
Runtime Only: This option allows empty values during runtime, while enforcing restrictions at other times, striking a balance between flexibility and data integrity.
Percentage: This setting allows a specified percentage of empty values, enabling some degree of flexibility while maintaining overall data completeness.
Validation Format Style: Choose the type of formatting to apply during the data export process. This setting determines how the data will be validated and structured. Available options include:
None – No specific formatting or validation is applied.
Date – Validates and formats data as date values based on the defined date format.
Numeric Value Range – Ensures that numerical data falls within a specified minimum and maximum range.
JSON – Validates the data as properly structured JSON, useful for exporting complex or nested data.
Validation Format: Defines the specific pattern or structure that must be used in combination with the selected Validation Format Style. This ensures that the exported data follows a consistent and expected format, improving data quality and clarity.
Display Format: Determines how the validated data will appear when presented or exported. It allows you to customize the layout or structure of the output for better readability and user experience.
Timezone handling: This setting allows you to specify how time zones are managed during data export. The options include:
Assume Local Time Zone: This option assumes that the times are in the local time zone of the system.
Assume Universal Time Zone: This setting treats all times as being in Universal Time (UTC), regardless of the local time.
Adjust to Universal Time: This option converts the local time to Universal Time (UTC), ensuring consistency in time representation across different regions.
Validation error handling: This setting determines the actions to take when a data validation error occurs. You can specify how to respond to such errors. The options include:
Report Error: Increases the error count while keeping the row in the export, allowing for later review of problematic data.
Report Failure: This option simply reports the failure.
Remove Data Row: Deletes the entire row from the export data, ensuring only valid entries are included.
Remove Data Row and Report Error: Removes empty rows from the export data and increases the error count when such rows are detected, helping maintain data integrity while tracking issues.